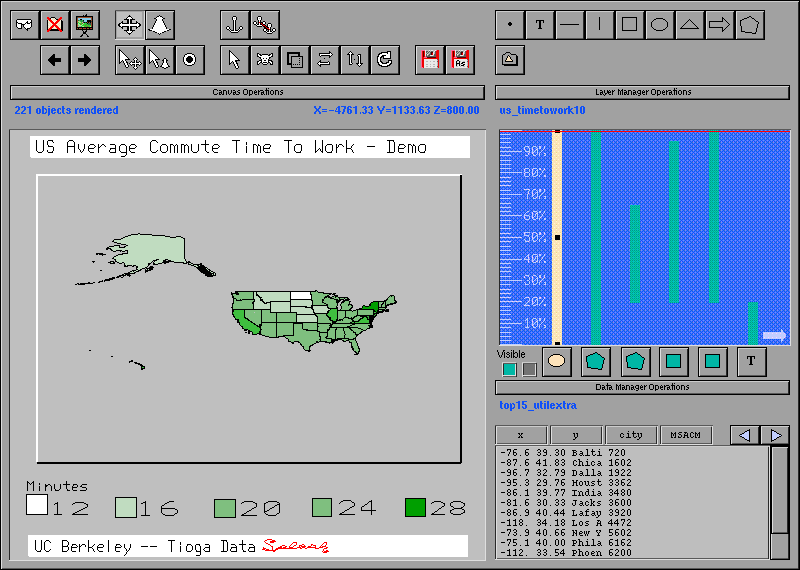
Figure 1: Visualization of average commute time in the United States
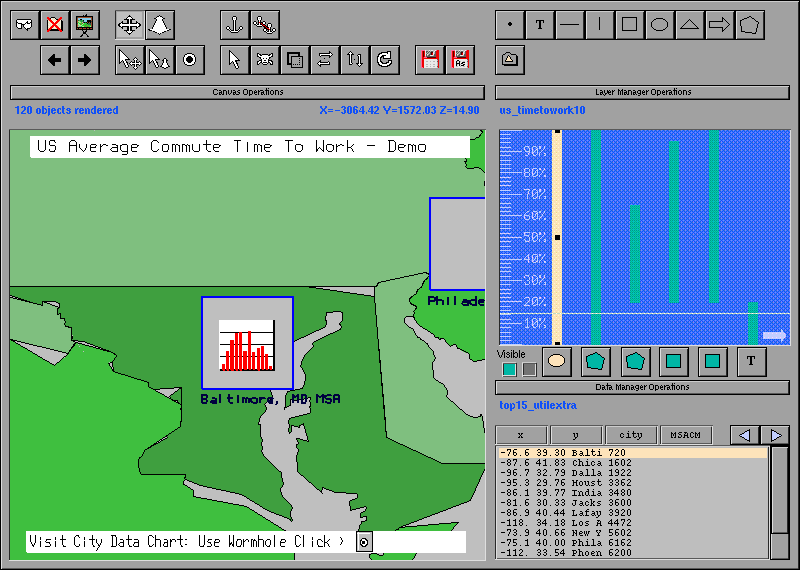
Figure 2: A visual link to another canvas
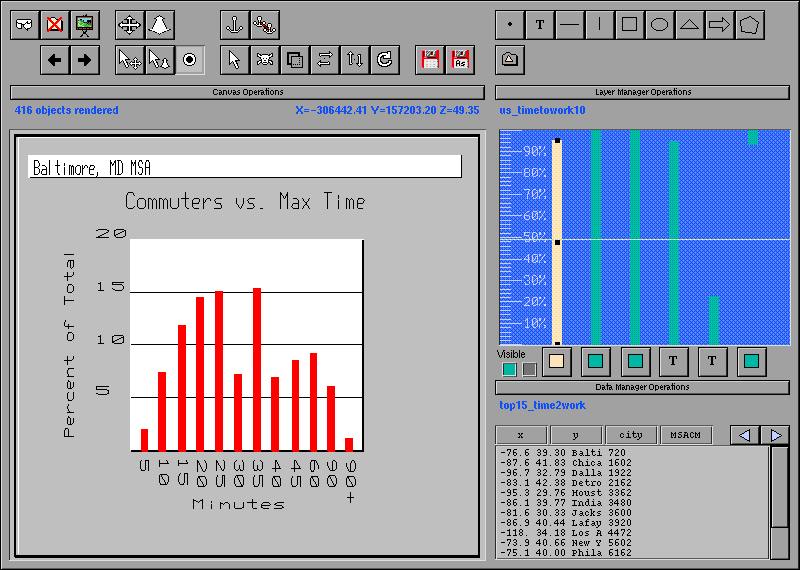
Figure 3: Histogram of commute time in Baltimore
Tioga DataSplash is a database visualization system. DataSplash has two primary goals: (1) to simplify the visualization process so that naive users can design custom visualizations; and (2) to provide an intuitive browsing model for navigating in visualizations.
To achieve the first goal, we have designed a paint program that is integrated with a database management system, POSTGRES95. This allows the user to program by directly manipulating the visualization. Our paint program contains most of the features of a conventional paint program. Unlike a standard paint program, however, our paint program accesses tables from the database management system. Objects in the visualization can be based on values from these tables [1].
To achieve the second goal (that of providing a sophisticated browsing interface), we have incorporated advanced features in the paint program. For example, objects in a canvas may be designated as visual links to other canvases. Furthermore, we provide a mechanism with which naive users can graphically program the way objects in a visualization will behave when users browse the visualization [2].
The first version of Tioga DataSplash is fully designed and implementation is nearly complete. Tioga DataSplash is built on top of POSTGRES95. We are using XForms for the user interface toolkit and OpenGL for the graphic visualization. Within two months, we plan to release a beta version of the software into the public domain.
Figure 1: Visualization of average commute time in the United States
Figure 2: A visual link to another canvas
Figure 3: Histogram of commute time in Baltimore
NOW-Sort is currently the fastest disk-to-disk sorting program, as measured by two well-known database benchmarks: Datamation and MinuteSort. NOW-Sort is a collection of sorting implementations on a cluster of Sun workstations connected with a high-speed Myrinet switch, and is adaptable to the number of available processors, the amount of main memory, and the number and the relative speed of the local disks. The parallel implementations of NOW-Sort are built on top of two key pieces of NOW technology, Active Messages and Glunix. To achieve high I/O performance and minimize communication, the layout of records to local disks is carefully managed.
The basic algorithm when all records fit in the collective memory of the workstations is as follows. Each processor reads its records from its local disk into main memory. A bucket sort determines the workstation that will contain this record after all have been sorted. Active Messages are used to send groups of records from the processor that read the key from disk to the destination workstation. After all records have been sent and received, each processor sorts its local keys and writes them to local disk.
When there are more records to be sorted than fit in the memory available in the cluster, two passes must be made over the records. In the first pass, the records are sorted into multiple runs according to the algorithm described above, where each run contains the number of records that fit in main memory. In the second pass, each processor merges the runs that reside on its local disk, writing out the final sorted run to another local disk.
We evaluate two different cluster environments. The first consists of 32 commodity UltraSPARC I workstations, each with 64 MB of memory. Each workstation houses two internal 5400 RPM Seagate Hawk disks on a single fast-narrow SCSI bus. The second cluster connects 8 more fully equipped UltraSPARCs. Each contains 128 MB of main memory and an extra fast wide SCSI card, with two 7200 Seagate Barracuda external disks. The workstations are connected through a Myrinet switch.
The Datamation sorting benchmark was introduced in 1985 by a group of database experts as a test of a processor's I/O subsystem and operating system. The performance metric is the time to sort 1 million 100-byte records, where the first 10-bytes are the key.
NOW-Sort performs the Datamation benchmark in 2.41 seconds, more than 1 second faster than the previous record (3.52 seconds, held by an SGI Challenge). This record was attained on the 32-node cluster of UltraSPARCs. Note that while the eight node cluster with four disks each has slightly worse performance (2.92 seconds), it has the best known cost-performance of 0.32 cents on this benchmark.
Recognizing that the Datamation benchmark has become more of a test of startup and shutdown time, MinuteSort was introduced in 1994. The performance metric is now the number of 100-byte records that can be sorted in one minute. NOW-Sort sorts 3.0 GB of data in 59 seconds, eclipsing the old mark of 1.6 GB, also held by the SGI Challenge Server.
NOWs are well-suited to I/O-intensive applications. The presence of multiple local disks per node enables a higher level of I/O performance than is traditionally possible from the I/O systems of MPPs.
Optimizing the single-node implementation is important for achieving scalable, high-performance parallel sorting algorithms. Examining the performance of individual workstations allows the programmer to isolate bottlenecks.
Disk I/O and fast communication can be overlapped, but the combination quickly stresses the limited bandwidth of the S-Bus in the UltraSPARC I. This bottleneck implies that an UltraSPARC with just two disks and a connection to a high-speed network may be the best building block.
64 MB of memory per machine is insufficient for the best performance on MinuteSort. Since we have insufficient memory to hold 3 GB on 32 machines, we must read and write all records to disk two times. We project that if each workstation had 320 MB of main memory, we could sort 3.1 GB in one minute on only 14 workstations.
Aggregation in traditional database systems is performed in batch mode: a query is submitted, the system processes a large volume of data over a long period of time, and, eventually, the final answer is returned. This archaic approach is frustrating to users, and has been abandoned in most other areas of computing.
The goal of this project is to support online aggregation in a database system, in which users can both observe the progress of their aggregation queries and control execution on the fly. We outline the usability and performance requirements for a system supporting online aggregation, and present a suite of techniques that extend a database system to meet these requirements. In addition, we provide formulas for computing running confidence intervals for a variety of aggregation queries encountered in practice; such intervals indicate to the user the proximity of the running aggregate to the final result.
Figure 1 is a sample online aggregation user interface, which shows the progression of a query that calculates average GPAs grouped by majors. Users can observe the results as the query is being processed. User control includes stopping a group, speeding up or slowing down a group, and adjusting the skip factor that controls the frequency at which the client is sent updated information. Also, statistical confidence interval is produced for the running aggregate, which is an important feature of our user interface.
We already have an initial implementation of online aggregation in POSTGRES including all of the functionality shown in the picture. To implement this functionality, we use a technique called index striding, which provides random delivery of values within each group, but chooses the groups in order (a tuple from group 1, then a tuple from group 2, and so on).
Initial results from our experiments serve as evidence that online aggregation yields more functionality and better performance than would be available in a naive solution.
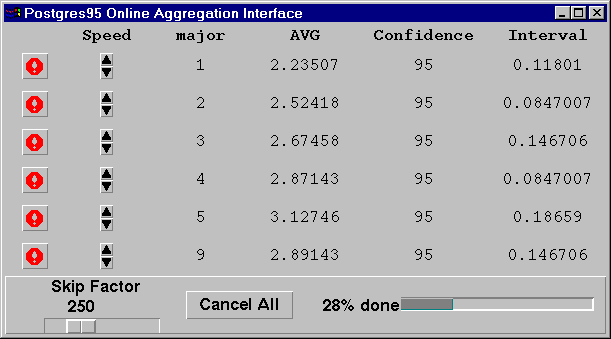
Figure 1: A sample online aggregation user interface
1IBM Almaden Research Center
The increasing popularity of object-relational features within database systems reflects the growing importance of having traditional database retrieval functionality for non-traditional applications. A key feature of these systems is fast, index-based access to the data, as well as support for datatype-specific operations along with the standard features of multiuser access, transactional isolation, and recoverability.
The research community has already developed a number of index structures for many kinds of non-traditional datatypes. Unfortunately, almost none of these are available in today's database systems. The reason is not that these new access methods have no performance benefits, but that the problems of concurrency control, isolation, and recovery have largely been ignored by prior research contributions. Furthermore, commercial quality implementations of full-featured access methods are typically very time-consuming.
The goal of our research was to develop general algorithms for concurrency control, recovery, and repeatable read isolation that can be applied to a very broad class of access methods. These algorithms were designed in the context of the generalized search tree (GiST) [1], a template index structure supporting an extensible set of datatypes and queries. Despite this, the algorithms are general enough to be applied individually to any particular access method that complies with the GiST structure.
Our concurrency control protocol is based on an extension of the link technique initially developed for B-trees and completely avoids holding tree node locks during I/Os. Repeatable read isolation is achieved with an efficient hybrid locking mechanism, which combines traditional two-phase locking of data records with predicate locking. In conjunction with these algorithms, the GiST can be the basis for access method extensibility in a commercial DBMS, allowing the addition of new access methods by providing a few hundred lines of extension code without having to deal with recovery or concurrency.
The results of our research are presented in [3].
In the Mariposa project, we are investigating the design issues in object-relational Distributed Database Management Systems (DDBMSs) as they scale to 10,000 or more nodes, in a geographically distributed network. One of the biggest challenges is designing and implementing update protocols that scale to networks of this size. Where existing protocols (i.e., distributed two-phase locking) require global synchronization at the end of every transaction, in Mariposa, we cannot afford to do this: not only does wide area network latency bottleneck the system, but among 10,000 computers, it is likely that one or more will be unavailable at any given time; thus, global synchronization would bottleneck the system waiting for unavailable hosts to come online again.
My thesis work is to design and implement a protocol that has better performance characteristics for this type of environment.
The Mariposa distributed database management system is an ongoing research project here at UC Berkeley. Mariposa takes a unique approach to distributed data management in order to achieve our goals, which include:
(1) Extreme scalability: our goal is for Mariposa to scale to 10,000 sites;
(2) Lightweight data movement: in traditional distributed database systems, moving data is a heavyweight operation that requires query processing to be halted while tables are moved. Mariposa allows database tables to change homes without interrupting query processing;
(3) Support for copies: copies provide increased availability and, in some cases, better response time. Mariposa supports copies as well as automatic copy creation and placement to maintain maximal system throughput in response to changing workloads;
(4) Data fragmentation: in Mariposa, tables can be horizontally partitioned. Data fragmentation can potentially increase parallelism during query execution. Tables can be fragmented randomly or by user-defined predicates; and
(5) High-performance query processing: the Mariposa system adapts its behavior in response to the workload placed upon it. The system uses a unique broker/bidder approach wherein sites bid against one another for work as well as for data. A Mariposa site can pay other sites to perform work or to sell it copies of data and can charge other sites for the same services.
Version 1.0 of Mariposa was released in June 1996. Currently, Mariposa runs on Digital Equipment Corporation's Alpha architecture running OSF/1. Ports to Sun's Solaris and Microsoft Windows NT are expected before 1997.