Document Size



After all markup had been extracted, the size of each HTML document
was measured. For the entire data set, the mean size was 4.4KB, the
median size was 2.0KB, and the maximum size was 1.6MB.
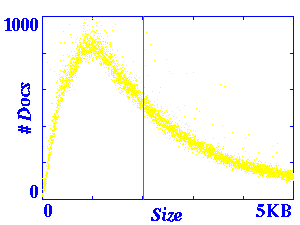
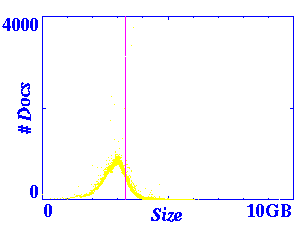
The graphs below present different views of the size distribution. On
first inspection, this distribution appears to be exponential (the
magenta line represents the location of the mean). However, further
zooming indicates a curve before the distribution begins to taper off.
The final graph contains a semilog plot of the same data (in which the
sizes are plotted logarithmically and the number of documents is
plotted arithmetically).


Size Distribution
These simple size distribution plots proved to be very useful in
detecting several problems with the data set. Many of the outliers
were caused by one of two major classes of errors:
- Problematic URLs: when faced with incorrect URLs that
contain valid prefixes, some HTTP servers return the file matching the
valid prefix. For example, the data set contains hundreds of
documents with URLs of the form
http://bazaar.com/underground2.html/..., all of which are
identical to http://bazaar.com/underground2.html. There
does not appear to be a general way for a client program (such as a
crawler) to differentiate this situation from a site containing a
large number of identical files.
- CGI Error Responses: some of the most popular CGI programs,
such as NCSA imagemap and CERN HTImage, report
errors with messages containing HTTP status ``200'' (success).
Because the image map programs all happen to return fixed error
messages, we were able to detect and eliminate those particular
messages, but there (again) does not appear to be any general way for
a client to distinguish ``200'' error messages from valid documents.